Warning: there is a bit of profanity. I’m warning you because profanity is obviously worse than being compared to Adolf Hitler. On the other hand, sometimes dirty words can be as funny as logical fallacies — and so can Hitler.
Adjectives for the Good and the Great

A well placed adjective can thoroughly change the meaning of a word. Some adjectives are so powerful that the the combined phrase becomes more significant than the noun the adjective modifies, leaving the unmodified noun seeming naked and weak without it. For instance, a cop is an important member of society, but a rogue cop is a thing of legend. An identity is good to maintain, but a secret identity is essential to maintain. A thief is a lowly member of society, but an identity thief is lower still. A secret identity thief is the lowest of all.
Then there are adjectives so overwhelming that they obliterate the word they modify, leaving none of the original meaning behind. A fallen angel, after all, is a devil, and a fair-weather friend is no friend at all.
I used to work for adjectives. You might have seen me on the side of the road holding a cardboard sign with words to that effect. I began my career as a junior developer, then worked up to being just a developer — which, although unmodified, was significant enough that it underscored the fact that "junior" was just a kind of slur. After developer came advanced developer, then expert developer, and finally senior developer. There are currently lots of senior developers around and very few junior developers, unlike the way it was back in the day. They all tend to wonder what comes after the adjective "senior". One can become an architect, of course, but the change of theme, and the fact that it is unmodified, merely serves to impress upon everyone that architects don’t actually do any coding. As a sort of gesture to make up for this damning through faint praise, an architect will occasionally receive a hyphenated title of developer-architect, which to my ear just makes things worse. After senior developer, one can also become a manager of course, much the same way a Jedi padwan can become a Sith lord, but this is a path of last resort.
Our Sith overlords could meliorate the situation by simply coming up with a new adjective, of course. I always thought awesome developer had a nice ring to it. Recent politics, besides revealing how our democracy really works, also inspired me with a different notion. The term super delegate left me wondering if super wouldn’t make a good modifier for the great developer. With repetition, we may be able to gentrify that somewhat wild modifier, super, and re-appropriate it from the comic connotations that have tended to diminish it. What better public identity is there for an über geek than super developer?
This morning, however, I was surprised to discover that there is something even more powerful in Democratic electoral politics than the super delegate. It is the undecided super delegate. Amazing, isn’t it, that not doing something can make a person more powerful than actually doing something? Rather than waste their potency by declaring for one candidate or the other, these undecided are able to curry special favor by simply not deciding, not declaring, not having an opinion one way or the other.
There is a tradition in the West that the undecided are in some sense the most contemptible beings, scorned by all sides. Before the gates of hell, Dante and Virgil encounter the third host of angels who neither sided with God nor with Satan, as well as those "who lived without or praise or blame," and perpetually lament their state. Virgil states harshly:
These of death
No hope may entertain: and their blind life
So meanly passes, that all other lots
They envy. Fame of them the world hath none,
Nor suffers; mercy and justice scorn them both.
Speak not of them, but look, and pass them by.
In the late Platonic school of Athens — alternatively known as the old school of Skepticism, or Pyrrhonic Skepticism –, on the other hand, this suspension of affirmation was considered a moral virtue, and was called the epoche (a term later appropriated by Husserl for Phenomenology). They found this suspension of belief so difficult, however, that they used ten argumentative tropes which they learned by heart to remind themselves that nothing should ever be asserted, lest they commit themselves to falsehood. The true philosopher, for the Pyrrhonic skeptic, is not one who speaks the truth, but rather one who does not speak falsehoods. Well into the modern era, one finds an echo of the Pyrrhonic tropes in Kant’s four antinomies.
Whether undecided super delegates are Pyrrhonists or Kantians I cannot say. I choose to withhold judgment on the matter since, after all, the real intent of this post is simply to congratulate two of my colleagues in the Magenic Atlanta office on their promotions. Through hard work and natural talent, Todd LeLoup and Douglas Marsh are now both Senior Consultants. With such adjectives we give public praise to the good and the great among us.
Learning Silverlight: Day Six

I’ve spent today going through all of the Hands-On-Labs provided on the silverlight.net site. The five labs are basically word documents, with some accompanying resources, covering various aspects of Silverlight 2 development. More importantly, they are extremely well written, and serve as the missing book for learning Silverlight. Should anyone ask you for a tech book recommendation for learning Silverlight 2 beta 1, you should definitely, emphatically, point them to these labs. They are both comprehensive and lucid. These labs are supposed to take an hour to an hour and a half each, so all tolled, it constitutes approximately seven hours of work.
1. Silverlight Fundamentals is a great overview of the features of Silverlight and how everything fits together. Even though it covers a lot of territory you may have come across in other material, it does it in a streamlined manner. In reading it, I was able to make a lot of connections that hadn’t occurred to me before. It is your basic introductory chapter.
2. Silverlight Networking and Data demonstrates various ways to get a Silverlight application to communicate with resources outside of itself using the WebClient and WebRequest classes. I couldn’t get the WebRequest project to work, but this may very well be my fault rather than the fault of the lab author. The lab also includes samples of connecting to RSS feeds, working with WCF and, interestingly, one exercise involving ADO.NET Data Services, a feature of the ASP.NET Extensions Preview.
3. Building Reusable Controls in Silverlight provides the best walkthrough I’ve seen not only of working with Silverlight User Controls but also with working between a Silverlight project and Microsoft Blend. This is also the only place I’ve found that gives the very helpful tidbit of information concerning adding a namespace declaration for the current namespace in your XAML page. I’m not sure why we have to do this, since in C# and VB a class is always aware of its namespace, and the XAML page is really just a partial class after compilation, after all — but there you are.
4. Silverlight and the Web Browser surprised me. In principle, I want to do everything in a Silverlight app using only compiled code, but the designers of Silverlight left open many openings for using HTML and JavaScript to get around any possible Silverlight limitations. This lab made me start thinking that all the time I have spent over the past two years on ASP.NET AJAX may not have been a complete waste after all. A word of warning, though. The last three parts of this lab instruct the user to open projects included with the lab as if the user will have the chance to complete the lab using them. It turns out that these projects include the completed versions of the lab exercises rather than the starting versions, so you don’t actually get a chance to work through these particular "hands-on" labs. On the other hand, this is the first substantial mistake I’ve found in the labs. Not bad.
5. Silverlight and Dynamic Animations begins with "This is a simple lawn mowing simulation…." The sentence brims with dramatic potential. Unlike the previous lab, the resources in Silverlight and Dynamic Animations include both a "before" and an "after" project, and it basically walks the user through using a "storyboard" to create an animation — and potentially a game. It’s Silverlight chic.
In retrospect, if I had to choose only one resource from which to learn Silverlight 2, it would be these labs. They’re clear, they’re complete, and best of all they’re free.
Popfly: Silverlight Game Designer

Have you always wanted to create a Flash game but found it too daunting? Microsoft’s Popfly site now lets you create Silverlight games using templates and pre-created images following a sort of wizard approach to game design. There are some working games on the site that you can start from, including a racing game and an Asteroids type game, and then modify with new behaviors or new animations to get the game you want.
The Popfly game creator is currently in alpha, and the intent is to make it easy enough for a child to use. To tell the truth, though, I’ve spent about 20 minutes on the site so far and still can’t quite figure out what is going on. All the same, it’s a great idea, and may be the sort of gateway tool that leads kids to want to use Visual Studio and Blend to create more sophisticated games until they are eventually fully hooked developers — if that is the sort of life you want for your children, of course.
***
Update 5/3/08: after three hours on Popfly yesterday afternoon, my seven year old son has created his own Silverlight game, while my daughter is learning the intricacies of Microsoft Blend 2.5 in order to create her own animations (the Popfly XAML editor is mostly disabled in this alpha version). I’m proud of their appetite for learning, but am nonplussed at the prospect for their future careers. I’d prefer that they become doctors or lawyers — or even philosophy professors — someday, rather than software developers like their old man. Then again, maybe in the world of tomorrow everyone will know how to work with Visual Studio 2020 and there will be no need for people like me who specialize in software programming. Software development might become an ancillary skill, like typing, which everyone is simply expected to know. Or maybe our computers will have learned to program themselves by that time.
It is an internal peculiarity of the software development professional that he constantly demands new tools and frameworks that will make programming simpler — the simpler the better — which in a sense is a demand to make his own skills obsolete. His consolation is found in Fred Brooks’s essay No Silver Bullet, which promises that there are essential complexities in software development that cannot be solved through tools or processes. The software developer is consequently an inherently conservative person who not only recognizes but also depends on the essential frailty of humanity and our inability to perfect ourselves. But what if this isn’t true? What if Brooks is wrong, and the tools eventually become simple enough that even a seven year old is able to build reliable business applications? That will be a bright day for the middle-manager who has to constantly deal with developers who want to tell him what cannot be done, thus limiting his personal and career potential. It might also be a beautiful day for humanity in general, but a dark, dark day for the professional software developer who will go the way of the powder monkey, the nomenclator, the ornatrix, the armpit plucker of ancient Rome, and of course the dodo.
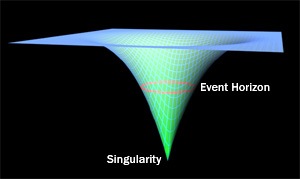
Slouching Towards The Singularity
This has been a whirlwind week at Magenic. Monday night Rocky Lhotka (the ‘h’ is silent and the ‘o’ is short, by the way), a Magenic evangelist and Microsoft Regional Director came into town and presented at the Atlanta .NET User’s Group. The developers at Magenic got a chance to throw questions at him before the event, and then got another chance to hear him at the User’s Group. The ANUG presentation was extremely good, first of all because Rocky didn’t use his power point presentation as a crutch, but rather had a complete presentation in his head for which the MPP slides — and later the code snippets (see Coding is not a Spectator Sport) — were merely illustrative. Second, in talking about how to put together an N-Layer application, he gave a great ten year history of application development, and the ways in which we continue to subscribe to architectures that were intended to solve yesterday’s problems. He spoke about N-Layer applications instead of N-Tier (even though it doesn’t roll off the tongue nearly as well) in order to emphasize the point that, unlike the in COM+ days, these do not always mean the same thing, and in fact all the gains we used to ascribe to N-Tier application — and the reason we always tried so hard to get it onto our resumes — can in fact be accomplished with a logical, rather than a physical, decoupling of the application stack. One part of the talk was actually interactive, as we tried to remember why we used to try to implement solutions using Microsoft Transaction Server and later COM+. It was because that was the only way we used to be able to get an application to scale, since the DBMS in a client-server app could typically only serve about 30 concurrent users. But back then, of course, we were running SQL Server 7 (after some polling, we audience agreed it was actually SQL Server 6.5 back in ’97) on a box with a Pentium 4 (after some polling, the audience concluded that it was a Pentium II) with 2 Gigs (it turned out to be 1 Gig or less) of RAM. In ten years time, the hardware and software for databases have improved dramatically, and so the case for an N-tier architecture (as opposed to an N-Layer architecture) in which we use two different servers in order to access data simply is not there any more. This is one example of how we continue to build applications to solve yesterday’s problems.
The reason we do this, of course, is that the technology is moving too fast to keep up with. As developers, we generally work with rules of thumb — which we then turn around and call best practices — the reasons for which are unclear to us, or simply become forgotten. Rocky is remarkable in being able to recall that history — and perhaps even for thinking of it as something worth remembering — and so is able to provide an interesting perspective on our tiger ride. But of course it is only going to get worse.
This is the premise of Vernor Vinge’s concept of The Singularity. Based loosely on Moore’s Law, Vinge (pronounced Vin-Jee) proposed that our ability to predict future technologies will collapse over time, so that if we could, say, predict technological innovation ten years in the future 50 years ago, today our prescience only extends some five years into the future. We are working, then, toward some moment in which our ability to predict technological progress will be so short that it is practically nothing. We won’t be able to tell what comes next. This will turn out to be a sort of secular chilianism in which AI’s happen, nanotechnology becomes commonplace, and many of the other plot devices of science fiction (excluding the ones that turn out to be physically impossible) become realities. The Singularity is essentially progress on speed.
There was some good chatting around after the user group and I got a chance to ask Jim Wooley his opinion of LINQ to SQL vs Entity Framework vs Astoria, and he gave some eyebrow raising answers which I can’t actually blog about because of various NDA’s with Microsoft and my word to Jim that I wouldn’t breath a word of what I’d heard (actually, I’m just trying to sound important — I actually can’t remember exactly what he told me, except that it was very interesting and came down to that old saw, ‘all politics are local’).
Tuesday was the Microsoft 2008 Launch Event, subtitled "Heroes Happen Here" (who comes up with this stuff?). I worked the Magenic kiosk, which turned out (from everything I heard) to be much more interesting that the talks. I got a chance to meet with lots of developers and found out what people are building ‘out there’. Turner Broadcasting just released a major internal app called Traffic, and is in the midst of implementing standards for WCF across the company. Matria Healthcare is looking at putting in an SOA infrastructure for their healthcare line of products. CCF – White Wolf, soon to be simply World of Darkness, apparently has the world’s largest SQL Server cluster with 120 blades servicing their Eve Online customers, and is preparing to release a new web site sometime next year for the World of Darkness line, with the possibility of using Silverlight in their storefront application. In short, lots of people are doing lots of cool things. I also finally got the chance to meet Bill Ryan at the launch, and he was as cool and as technically competent as I had imagined.
Tuesday night Rocky presented on WPF and Silverlight at the monthly Magenic tech night. As far as I know, these are Magenic only events, which is a shame because lots of interesting and blunt questions get asked — due in some part to the free flowing beer. Afterwards we stayed up playing Rock Band on the XBOX 360. Realizing that we didn’t particularly want to do the first set of songs, various people fired up their browsers to find the cheat codes so we could unlock the advanced songs, and we finished the night with Rocky singing Rush and Metallica. In all fairness, no one can really do Tom Sawyer justice. Rocky’s rendition of Enter Sandman, on the other hand, was uncanny.
Wednesday was a sales call with Rocky in the morning, though pretty much I felt like a third wheel and spent my time drinking the client’s coffee and listening to Rocky explain things slightly over my head, followed by technical interviews at the Magenic offices. Basically a full week, and I’m only now getting back to my Silverlight in Seven Days experiment — will I ever finish it?
Before he left, I did get a chance to ask Rocky the question I’ve always wanted to ask him. By chance I’ve run into lots of smart people over the years — in philosophy, in government, and in technology — and I always work my way up to asking them this one thing. Typically they ignore me or they change the subject. Rocky was kind enough to let me complete my question at least, so I did. I asked him if he thought I should make my retirement plans around the prospect of The Singularity. Sadly he laughed, but at least he laughed heartily, and we moved on to talking about the works of Louis L’Amour.
The Secret Society of Liberal Artists

The IT industry is dominated by those with CS degrees. Much criticism has been leveled at the CS degree of late, mostly on the grounds that it doesn’t provide the skills (or even teach the languages) that an aspiring software developer will need once she gets out into the real world. Brian at Enfranchised Mind has a good post over on his blog about this. He raises what he considers to be three misconceptions concerning IT and the CS degree:
- Computer science and programming are separate things, and that it’s possible to know one without knowing the other,
- That it is possible, at least in theory, to teach students everything (or most everything) they need to know in “the real world”, in a reasonable amount of time (four years), and
- That the point and purpose of a CS education is to give you those “real world” skills.
He argues, correctly I believe, that the goal of the Computer Science Degree is not to provide students with a specific set of skills to do a specific job, but rather the sort of skills they will need to perform any IT job. This has both practical and humanistic implications. From a practical point of view, being trained to do a specific job in IT is inherently short sighted, since technology changes so quickly that the person trained to do the most needed tasks today — say MS BizTalk, or MS SharePoint, or SOA architecture — may find himself obsolete within five years.
Job training is also wrong from the humanistic perspective, however. To be trained for a job is basically to be trained to be a cog in a wheel. This doesn’t work in professions that require the amount of energy, thought, and imagination required to successfully complete software projects. Instead, some thought has to be put into developing the whole person to participate in the complex activity of software development, and this means equipping that person with the skills needed to not only understand the things that have to be done immediately, but also to understand the principles behind what they do, and the goals they are trying to achieve. This in turn involves developing the whole individual in a way which, on the surface, appears to be useless. CS majors learn obsolete languages and the principles behind building tools that have already been developed for them out in the real world. Why learn to build a web server when there are so many already out there?
What is forgotten in these arguments against CS is that the goal of the degree is not to teach CS majors how to do any particular IT task, but rather how to think about IT. In learning obsolete languages, they learn to think about software in a pure way that does not involve immediate applications or utilitarian motives. They learn to appreciate computer science for its own sake. In the long run, this useless knowledge can also become useful knowledge. When code start breaking, when servers don’t work as advertised, it is the CS major who is able to step in and unravel the problems because they understand what the server or the code is supposed to do. They understand the principles. For a great article on the purpose of useless knowledge, I highly recommend Stanley Fish’s post from earlier this year.
While the IT industry is dominated by CS majors, it is not exclusive to CS majors. Over the years accountants, actuaries, mathematicians, physicists, entomologists and ornithologists have also found their way into the profession, and have enriched it with their particular perspectives. The rigor of their training has turned out to provide much needed additional skills to the mix. The mathematician knows his way around algorithms much better than the typical CS major. The ornithologist is trained to organize and particularize in ways those with CS degrees are not. Accountants and actuaries know the secret paths of financial transactions that your common CS major cannot usually follow. These specialists have basically learned on the job, and their prior careers have provided them with the techniques of methodical thinking as well as the strong grounding in mathematics necessary to make this transition possible.
But the IT industry is not exclusive to CS majors and emigres from finance and the sciences. Within the hallowed cubicles of IT you will also find secret adepts of the Trivium, followers of disciplines which since the beginning of the 20th century have been generally acknowledged as being trivial. These are the practitioners of truly useless knowledge: English majors, philosophy majors, psychology majors, comparative literature and art history majors. You may work in an IT shop infiltrated by these people. You may even have a French literature major working in the cubicle across from yours and not even know it. Your DBA could be a history major. The etiquette of the IT workplace prevents you from finding this sort of thing out. You have no way of knowing.
But they know. Liberal artists seek each other out, and have secret phrases they use to find each other that seem like gobbledygook to the rest of us. Has a colleague ever asked, in passing, if you read Auden? You probably gave a confused look, and the interlocutor quickly changed the subject. You’ve probably even forgotten about the incident, not understanding the implications of the phrase.
What was really going on, though, was this: you were being approached by a Liberal Artist who, for whatever reason, suspected that you might also be a Liberal Artist. Perhaps you dressed with a bit of extra flair that day, or took some care in matching your belt with your shoes, or applied a subtle and inoffensive amount of cologne. There are lots of secret signs in the Liberal Artist community. Whatever it was, you were then approached in a "contact" scenario to discover if you were in fact an initiate or merely someone who accidentally deviated from the norm of the IT dress code (i.e. golf shirt, khaki pants with frayed cuffs, tech gear worn on utility belt). Your bewildered look, in turn, indicated one of two things: 1) I have no idea what you are talking about or 2) there are other people listening in — too dangerous to make contact now — come back later.
Other phrases that might be used by a liberal artist during a "contact" situation include:
- I read an article in Archaeology Today that might be relevant to this.
- I hear the Pinot Gris is especially tasty this year.
- That is quite a moral quandary. I wonder what Kant would say.
- This debate over objects vs services reminds me of the Medieval debate between Realists and Nominalists.
- Did you see that New Yorker cartoon? You know the one I’m talking about.
- That is not the proper usage for "begs the question." What you meant to say is it "invites the question."
- Are you as incensed as I am by Stanley Fish’s latest blog post?
This of course does not exhaust the list of occult phrases that may be used by the liberal artist during an attempted contact, but it should give you a good indication of the types of things you might look for in order to find signs of liberal artist infiltration of your organization. Another way to identify liberal artists without breaking etiquette and outright asking them — thus revealing that you are onto their little game, and possibly placing yourself in a precarious position — is to ask what schools they attended. Even better, surreptitiously check their resumes to gather this information. Sometimes the matter may be ambiguous. On the other hand, if you find that they attended schools with names like Bard, Brown or Bowdoin, then you can be fairly certain that you are face-to-face with a liberal artist. Here is a list of other liberal arts schools you can use in your background check.
Why, you may ask, are liberal artists so secretive about their background, to the point that they require secret signals to identify one another? An innocent explanation would be that they simply suffer from a bit of CS envy, and desire to blend in. But this wouldn’t be the whole story. Liberal artists help each other out. By identifying each other in these esoteric ways, they not only form a cohesive unit within an organization, but put themselves in positions to help one another out. Like a fifth column inside the corporate body, they concentrate power into the hands of like-minded individuals, and use this as leverage in order further climb the corporate ladder.
Consider how many of your managers might be liberal artists. Liberal artists are often able to emphasize their communication skills based on their backgrounds, which tends to put them on a management track. Once in management, they are in turn more likely to favor others with a similar background for promotions. It is a vicious circle that leads, in many companies, to a situation in which you may find that while the IT staff is predominantly made up of CS majors, the class of employees tasked with managing the CS majors are almost exclusively humanities majors. And how does this happen? Through simple and apparently innocuous questions like "Do you read Auden?"
Don’t believe me? Then consider that Carly Fiorini, the former CEO of Hewlett-Packard responsible for the merger with Compaq, is a medieval history and philosophy major. Michael Eisner, one of the best paid CEO’s ever, studied English and theater. Sue Kronick, one of the 25 highest paid executives in the U.S. according to Fortune Magazine, did Asian studies in college. So the next time you are tempted to think of the Secret Society of Liberal Artists as a mere social organization, consider carefully who holds the reins of power in your company. The Secret Society of Liberal Artists: a harmless networking tool? Perhaps. A dangerous anti-democratic cult out to gather power by any means? Most definitely.
How do I know all this? Because, my friends, I must confess that I am not only a software programmer. I am also a recovering liberal artist. And I am here to warn you: do not take the liberal arts lightly.
How to Read a Tech Book

My efforts to write about learning Silverlight in Seven Days are filled with omissions and gaps. While each Silverlight "day" really does constitute one day’s worth of studying, they haven’t been contiguous days. One large gap is due to a trip I had to make to Washington D.C. to settle personal affairs. Others were job related since, like most of you, I have to maintain my day job even as I’m expending effort to learn new technology in my off time — which, however, will eventually feed back into my day job. Which invites the obvious question of whether learning technology is really work time or private time. I tend to think of it as private time, since I enjoy it immensely and grow personally by doing it. All the same — and I believe this is not the case in most IT shops — my day job is actually forward looking about this sort of thing, and allows me to spend part of my day learning all the new acronyms coming out of Redmond — in some sense paying me to do something I love. But an equally valid way of looking at it is that I am working to keep my IT shop informed about the best solutions for its upcoming projects, and the reward for the investment of time and energy I make in learning these technologies are ultimately reaped by my company. I am, in effect, investing my company’s time wisely.
Should we choose to look at the matter in this way, then it is important that the time spent on learning technology be used optimally. This is hampered by the fact that information about things like WCF, WPF, WF (the initial "W" is typically truncated, I assume, because it evokes notions of profession wrestling) and Silverlight are poorly disseminated. Half of the effort spent on learning new tech involves tracking down the proper resources, weeding out the unhelpful books that misstate what they can offer and the ones that are just poorly written or misinformed, and finding the correct location for the online resources — including source code — that one needs. Scott Galloway has a great post about this problem over on his blog: http://www.mostlylucid.net/.
The other half is spent actually engorging all the information that is available. There is a scene from Johnny Mnemonic, that peculiar 1995 Keanu Reeves sci-fi vehicle, in which Keanu uploads 300 megabytes of data into his cerebral cortex. In order to prepare for it, he puts a bite guard in his mouth, clamps down and, with evident consternation on his face, yells out "hit me." This is how I feel whenever I prepare myself to sit down with a tech book.
A tech book is not a friendly beast. You cannot curl up with it in bed. You never giggle over a clever turn of phrase and beg your partner to allow you to read her a passage aloud. Instead, it is a big heap of bound paper, generally printed in large type in an apparent attempt to make it seem weightier than it has any right to be, which you have to plow through in a Sisyphusian effort to reach the end. In truth, no one ever gets to the end of one of these things because we all get bogged down in the details. This is natural enough, because the presentation is typically all about the details after the initial chapter, and the initial chapter tends to alternate between vagueness and hello world samples to the point that it just can’t be taken very seriously. But then we get lost in the details. There is so much we don’t understand in reading through these tech books that we become frantic over the thought that we might be missing something important — the key that unlocks all the material we are trying to absorb. The reading process becomes slower and more onerous until finally external affairs draw us back into the life-world or we throw our tech book to the wall where, with luck, it shatters into a million pieces and we never have to pick up reading again where we left off.
Scott Hanselman touches on this point in his post: Books: We Need More So What, Now What, And What For And Less Just What, though it might just as easily have been titled, "Why Tech Books Suck". The essential problem with tech books is that they never work out the inherent paradox of all learning: one cannot learn the whole without understanding the parts; one cannot know the parts without understanding the whole. In contemporary exegetics, this known as the hermeneutic circle.
Aristotle says in his Poetics that tragedies such as Oedipus Rex and Electra are higher and more philosophical than historical works because they aspire to truth, whereas histories merely offer details. I think it is this desire to know the "truth" of a technology — its purpose, its potential, it’s meaning — from a medium so poorly suited to this task, the tech book, that typically leaves us feeling so frustrated and so drained. We get bogged down in details because tech authors get bogged down in details, and it is the exceptional writer who knows how to navigate the hermeneutic circle in order to provide us with a usable tech book — the criterion for usability, in this case, being merely not making us want to throw it across the room.
The quality of tech books is out of our control, however, so we must turn to the quality of reading tech books. Here are my suggestions for how to get the most out of a tech book, so that as little time is wasted on them as possible:
1. Read Online — I use Safari Books Online for my tech education, as well as MSDN and various tech blogs. This tends to make my eyes bleed, but it has the distinct advantage of not lulling me into the illusion that tech books are like other books. Once I start treating tech books like other books, I find that I fall into the habits I’ve acquired for reading fiction and even most non-fiction. I look for a plot and my mind tries to work itself towards a narrative climax that never actually transpires. Tech books don’t have plots. They just are. If you rip out the chapters and put them together in a different sequence, it generally doesn’t matter. Tech books are heaps, not paths. Reading online helps me to avoid this confusion — though it obviously isn’t for everyone.
2. Plan to Re-read — if you set out on a new book knowing that you will re-read it, then you won’t get so bogged down in the details. You can always go back and pick up what you missed later. I generally read a tech book three times. The first time I just skim through the chapter headings so I know what the book is going to cover and what I feel confident about skipping entirely. This can be done in a few minutes. On the second read, I just skim the whole book. I don’t try to do any coding exercises. I just get a good grasp of the principles involved, and the various materials I will need to understand. The goal is simply to get to the end of the book, not to understand it in its entirety. This can be done in a few hours. The third read is used to go back and pick up the important stuff. From the second read, I know that there are things I don’t understand, and hopefully I will have formed an opinion of what is important in the book and what is drivel. In the third read, if a third read is even necessary, I pick up the important bits.
3. Give Yourself Permission to Skip — The fear of missing something important is a paralyzing fear. You have to give yourself permission to skip things when you are reading a tech book. Remember, a lot of the things in a tech book are just filler. The author felt he had to push something in that is actually irrelevant, or the publisher has established a page count for him that he must fulfill. Not everything in a tech book is important. Marshall McLuhan developed a habit of reading only the right hand pages of any non-fiction book (he would read a non-fiction book in its entirety, however). The way he explained it, a lot of non-fiction is just filler, and by his estimation, only 10% or so of any non-fiction book was actually worth knowing — and that was if it was a good book. An intelligent person can fill in the gaps as he goes along. More importantly, the way your mind fills in these interstitial gaps actually helps it to retain information better. The mind learns not by simply replicating what it finds in a book, like some copying machine, but rather by trying to reconstruct and build things in the imagination. In rhetoric, this is sometimes called an enthememe, or a logical argument with gaps. The ancient orators discovered that by not completing a logical argument, but rather by letting an audience piece it out for themselves, they were better able to convince the audience of the rightness of their conclusions. Laying things out for people leaves them unconvinced. Making them work things out for themselves gives them possession of the information, and allows them to make it their own.
4. Talk About What You Learn — Reading a book is useless if you can’t retain what you’ve learned. The best way to retain the information in a tech book is to use it. Unfortunately we aren’t always afforded opportunities to use what we know. We do, however, always have outlets to talk about what we know, and the process of talking not only forms new neural pathways in our brains, thus increasing retention, but allows us to correct our mistakes and misconceptions. Talking to other developers working on the same technology is optimal. If that is not possible, however, blogging or writing to newsgroups can serve the same function. They keep the technology ever in your mind, and you can add on to it or take away from it as you go along.
All of this may be pretty obvious, but then one would think that figuring out how to write better tech books should also be pretty obvious — and it isn’t. Learning new technologies is generally considered one of the "soft" problems of IT. By now, however, we have all had enough industry experience with reading tech books that it is clear this is not the case, and it is probably time to throw tech books onto the mound with all of the other "hard" problems of IT, like how to retain good people and how to complete a project on time.
Navel Gazing

In Greek, it is called Omphaloskepsis — though the provenance of this term appears to be fairly recent. Its origins seem to be found in Eastern meditative practices in which the subject concentrates on his navel, the center of his being, in order to shut out all worldly distractions. The significance of the navel is also found in the origins of Western culture. Omphalos, literally "navel", was used to describe the terrestrial location from which all life sprang. It was also the name of the stone found in the temple at Delphi, purported to be the stone which Rhea swaddled in baby clothes and which the titan Chronos swallowed, believing it to be his son Zeus, prophesied to one day overthrow him. Because of its divine origins, the Omphalos was believed to be a point of contact between the celestial and the terrestrial, and gazing at the Omphalos was equivalent to gazing into the realm of the gods.
It is also a mode of reflection common in times of uncertainty. The IT industry is at such a point. Any software professional who went through the .NET bust at the turn of the millennium and through the financial decline following 9/11 has an ingrained sense that changes in the economy can radically alter the face of IT. The past five years have seen the emergence and adoption of various tools and methodologies, from Agile to Responsibility Driven Design to Domain Driven Design to alt.net, all premised on the notion that things haven’t been going well, and if we all just put our heads together we will find a better way.
Marshall McLuhan — I believe it was in The Medium is the Massage — tells an anecdote about a factory that brought in consultants to change their internal processes, resulting in a 10% increase in productivity. A year later, for unspecified reasons, the factory reverted to its previous processes, and surprisingly increased productivity by another 10%. This suggested to McLuhan that sometimes what one does to bring about change is not significant in itself. Sometimes it is simply the message of change, rather than any particular implementation, which provides results.
The various methodologies, philosophies and practices of the past few years seem to have made improvements in some software houses, but it is not clear that this is due to the inherent wisdom of the prescribed techniques rather than, as McLuhan might say, the simple message that things aren’t quite right with our industry. The acolytes of each methodology that comes along initially cite, quite properly, Fred Brooks’s influential articles The Mythical Man-Month and No Silver Bullet. What they rarely do, once their movements achieve a certain momentum, is revisit those early arguments and evaluate whether they have accomplished what they set out to do. Did they solve the problems raised by Fred Brooks? Or do they just move on and "evolve"?
Besides all the process related changes that have been introduced over the pass few years, Redmond is currently caught up in a flurry activity, and has been releasing not only new versions of their standard development tools, but a slew of alpha and beta frameworks for new technologies such as Presentation Foundation, Silverlight, Entities Framework, and MVP which threaten to radically alter the playing field, and leaves developers in a quandary about whether to become early adopters — risking the investment of lots of energy for technology that may potentially never catch on (DNA and Microsoft’s DHTML come to mind) — or stick with (now) traditional windows forms and web forms development, which may potentially become obsolete.
We also face the problem of too many senior developers. There was a time when the .NET bubble drove all companies to promote developers rapidly in order to keep them, a tendency that kept expectations high and that did not really end with the collapse of the bubble. Along with this, companies set the standard for senior developers, generally the highest level developers can attain short of management, as someone with ten years of development experience, a standard which, given the compact time frames of the IT industry, must have seemed a long way off. But now we have lots of people in lots of IT departments with 10 years of experience, and they expect to be confirmed as senior developers. Those that are already senior developers are wondering what their career path is, and management is not particularly forthcoming.
The combination of these factors means the IT population is graying but not necessarily maturing. Management in turn is looking at ways to outsource their IT labor, under the misapprehension that IT fits into an assembly line labor model rather than a professional model in which system and business knowledge should ideally be preserved in-house. IT, for most companies, falls on the expense side of the ledger, and one expects to find ways to make it more efficient. The immature state of the profession, compared to medicine or teaching or even engineering, makes these efficiencies difficult to find.
Add to this an economy headed toward a recession or already in recession, and we have all the necessary ingredients for a period of deep navel gazing. My feed reader recently picked up three, and I suspect this is only the beginning.
Martin Fowler’s Bliki contains a recent entry on SchoolsOfSoftwareDevelopment which deals with the problem of competing methodologies, and the Habermassian problem of agreeing on a common set of criteria upon which they may be judged.
Instead what we see is a situation where there are several schools of software development, each with its own definitions and statements of good practice. As a profession we need to recognize that multiple schools exist, and that their approaches to software development are quite different. Different to the point that what one school considers to be exemplary is considered by other schools to be incompetent. Furthermore, we don’t know which schools are right (in part because we CannotMeasureProductivity) although each school thinks of itself as right, with varying degrees of tolerance for the others.
A Canadian developer, D’Arcy from Winnipeg, wonders what the new Microsoft technology map entails for him.
For the last 7 years we’ve been learning the web form framework, learning the ins and outs of state management (regardless of your opinion if its good or bad), how to manage postbacks, and how to make the web bend and do summersaults based on what our needs were. And here we are again, looking at the next big paradigm shift: Webforms are still around, Rails-like frameworks are the new trend, and we have a vector based Flash-like framework that we can code in .NET. I find it funny that so many are wondering whether web forms will go away because of the new MVC framework Microsoft is developing, and *totally* ignore the bigger threat: being able to develop winform-like applications that will run on the web using Silverlight.
Finally, Shawn Wildermuth, the ADOGuy, has posted an existential rant on the state of the industry and the mercenary mentality on the part of management as well as labor, and the long-term implications of this trend.
In some sense we developers are part of the problem. Quitting your $75K/yr job to be hired back at $75/hr seems like a good deal, but in fact it is not a good deal for either party. Your loyalty is to the paycheck and when you leave, the domain knowledge goes with you…
At the end of the contract you just move on, forcing you to divest in a personal stake. I miss that part of this business. I have had more enjoyment about projects that didn’t work than all the mercenary positions I’ve ever held…
So do I have a call for action? No. I think that domain knowledge is an important idea that both developers and companies need to address, but I don’t have a nice and tidy solution. This is a shift that I think has to happen in software development. Both sides of the table need to look long at the last five to ten years and determine if what we’re doing now is better than before. Does it only feel better because each line of code is cheaper to produce (mostly a product of better platforms, not better coders). I hope this can change.
Something is in the air. A sense of uneasiness. A rising dissatisfaction. An incipient awareness of mauvaise foi. Or perhaps just a feeling that the world is about to change around us, and we fear being left behind either because we didn’t try hard enough, or because we weren’t paying attention.
Learning Silverlight: Day Five

Day five picks up with unsolicited errata and general notes for the remaining Quick Start tutorials from the Silverlight.net site.
Notes to Interaction Between HTML and Managed Code (there is only one tutorial in this section, as of this writing):
Accessing the HTML DOM from Managed Code — This is a pleasant tutorial showing how to use the Silverlight Host Control as basically a wedge between code behind and the HTML DOM. From the user control hosted in the host page, you can basically grab the DOM of the container page and manipulate it. Because there is a lot of code, this is primarily a copy & paste style of tutorial, which means some useful information is left out. For instance:
- If you name your Silverlight project qsHB, the code will work better, depending on how much you copy & paste and how much you write by hand.
- The HTML controls you add to the Test html page should go in the same div tag that contains the Silverlight Host object.
- By default, the dimensions of the Test html page generated with your project are 100% by 100%. Change this to 10% by 10%, otherwise your controls will be off the bottom of the browser window.
Notes to Programming with Dynamic Languages (this section only has one eponymous Quick Start):
Notes to Programming with Dynamic Languages: [Skipped] — some day I may want to learn managed JavaScript, IronPython, or IronRuby. Right now, however, I can’t really see the point.
Notes to Additional Programming Tasks (includes one Quick Start):
Using Isolated Storage and Application Settings — This tutorial walks you through working with the System.IO.IsolatedStorage.IsolatedStorageFileStream, which allows the application to store files in a sandbox on the server. The application is very rich, which unfortunately means the tutorial itself involves a lot of copy — paste — compile. To understand what is going on, you basically need to read through all the code you copy & pasted after it is all done. When a tutorial becomes this complex (and to my chagrin I have written a few like that) it is perhaps best to give up on the idea of doing a tutorial and actually do a "lab", in which the code is already all written out, and the author’s job is merely to walk the reader through what is going on. This is a cool little application, all the same, and I foresee using it as a reference app for lots of future projects.
Whew. That’s it for the Quick Starts found on http://silverlight.net. Tomorrow I’ll start on the labs.
Learning Silverlight: Day Four

Day Three concluded with finishing the QuickStart series on Building Dynamic User Interfaces with Silverlight, from the official Silverlight website. Day Four continues with notes and unsolicited errata on Networking and Communication in Silverlight.
A. Sending and Receiving Plain XML Messages with Silverlight — I learned a new acronym in this very brief tutorial. POX stands for plain ol’ XML. The System.Net.WebClient class allows us to call a web service (in this case, a DIGG service) and pass the results to a callback method.
B. Building a WCF Web Service and Accessing It by Using a Proxy — Very nice. A somewhat sophisticated small application combining Silverlight and WCF, explained clearly. Someone went through and proofread this particular walkthrough, and the effort shows even in the details — like stating what namespaces need to be referenced before one actually needs to use them.
C. Accessing Syndication Feeds with Silverlight — Very simple tutorial on how to access an rss feed in Silverlight using the System.ServiceModel.Syndication.SyndicationFeed class. The only problem is that if you follow the instructions precisely, it will not work. The sample code uses the Silverlight.net rss feed, http://silverlight.net/blogs/microsoft/rss.aspx, as its source. Unfortunately, in order to access an rss feed, the server hosting the feed must have a policy file set up to allow cross-domain access, which the Silverlight.net rss feed does not.
A tad annoying, no? Or perhaps this is a some sort of Zen exercise intended to reinforce the principle that a Clientaccesspolicy.xml or Crossdomain.xml file must always be properly configured on the feed server.